
არჩევნების შედეგებზე პოლიტიკური ნეირომარკეტინგის 2.0 გავლენა – II
2016 წლის ტრამპის საპრეზიდენტო კამპანიის ქეისი
Big data 2.0-ის პოლიტიკა.
მანამ, სანამ big data 2.0-ს კონცეფციას განვსაზღვრავთ და პოლიტიკაში, განსაკუთრებით პოლიტიკური მარკეტინგში, გამოყენების იდენტიფიცირებას მოვახდენთ, მოცემულ სტატიაში, თავდაპირველად აუცილებელია მონაცემებსა და ინფორმაციას შორის განსხვავების დადგენა.
ჩვეულებრივ, მონაცემები, განმეორებით დახარისხების, გადაჯგუფების, ანალიზის და ცოდნის ფაზაში სხვაგვარი გადასვლის წინ, ინფორმაციის ნედლ სურათს წარმოადგენს.
ორგანიზებულობის ხარისხიდან გამომდინარე მონაცემები
- სტრუქტურულ,
- არასტრუქტურულ და
- ნახევრადსტრუქტურულად იყოფა.
გადაწყვეტილებების და პოლიტიკის შემუშავებისას ყველა ეს მონაცემი, ტექნიკური მანიპულაციების ჩატარების გარეშე არ გამოიყენება.
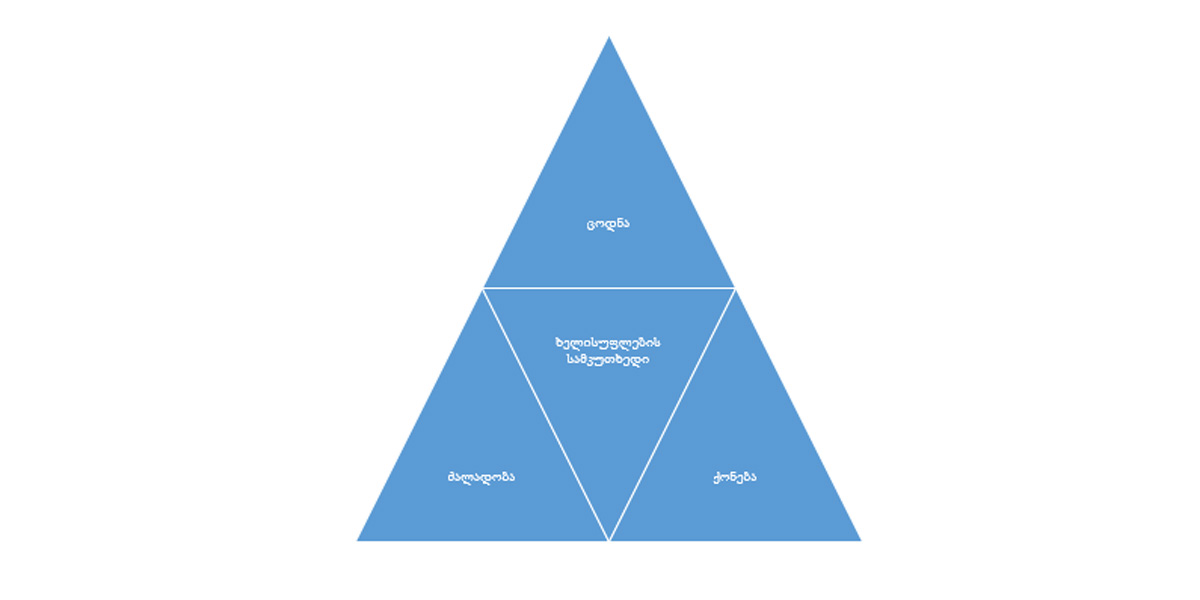
დაახლოებით 49 წლის წინ ტოფლერმა (1970) წიგნში „მომავლის შოკი“ (Future Shock) მომავალში, პოლიტიკაში ინფორმაციის და ერუდიციის მნიშვნელობის აუცილებლობას ხაზი გაუსვა, როდესაც აღნიშნა, რომ ხელისუფლების სამკუთხედი სამი ძირითადი გვერდისგან შედგება: ცოდნა/ერუდიცია, ქონება/მატერიალური ფასეულობები და ძალადობა – knowledge, wealth and violence. უფრო მეტიც, მან იწინასწარმეტყველა, რომ ერუდიცია და არა მატერიალური ფასეულობები და ძალა, გლობალური კონკურენციის და ინფორმაციული ტექნოლოგიების რევოლუციის ეპოქაში გახდება ხელისუფლების არსი, ვინაიდან ავტორი აკვირდებოდა ქვეყნებში მიმდინარე „ინფორმაციულ ომებს“.
ფიგურა 1: ტოფლერის ხელისუფლების სამკუთხედი (Toffler, 1970)
 Big data 2.0 შეიძლება უბრალოდ განისაზღვროს, როგორც Web 2.0-ის ეპოქაში „ყველა წყაროდან შეგროვებული ციფრული მონაცემების უზარმაზარი რაოდენობის საერთო ტერმინი“. ეს მონაცემები „რელაციურ მონაცემთა ბაზის ტრადიციული მეთოდების მეშვეობით ანალიზისათვის საკმაოდ მოცულობითი, დაუმუშავებელი ან არაკონსტრურებულია“ (Kim et al., 2014, с. 78). მონაცემების ინტელექტუალური ანალიზით დაკავებული მეცნიერების დიდი ნაწილი ამტკიცებს, რომ ამ ფორმით, big data 2.0 სამ შიდა მაჩვენებელზეა დაფუძნებული – მოცულობა, სიჩქარე და სხვადასხვაობა ან იმაზე, რასაც ზოგადად big data-ს “3 Vs”-ს უწოდებენ (Lycett, 2013). ზოგიერთმა მეცნიერმა, სამ მაჩვენებლს, რომელზედაც big data-ს განსაზღვრებაა დაფუძნებული, უბრალოდ დაუმატეს სანდოობა და ფასეულობა (Rajaraman, 2016). Joseph Hellerstein-ი, ბერკლის უნივერსიტეტის გამოთვლითი ტექნიკის პროფესორი, ერთ-ერთი პირველთაგანი იყო, ვინც „მონაცემთა სამრეწველო რევოლუციაზე“ მიუთითა (Hellerstein, 2008). IBM-ის შეფასებით, ამჟამად, მსოფლიოში მიღებული მონაცემების თითქმის 90% მხოოლოდ 2 წელიწადშია შეკრებილი, ამასთან ყოველდღიურად მონაცემთა 2,5 კვინტილიონი ბაიტი ემატება (Jacobson, 2013), რაც, რათქმაუნდა, მნიშვნელოვანი ზრდაა.
Big data 2.0 შეიძლება უბრალოდ განისაზღვროს, როგორც Web 2.0-ის ეპოქაში „ყველა წყაროდან შეგროვებული ციფრული მონაცემების უზარმაზარი რაოდენობის საერთო ტერმინი“. ეს მონაცემები „რელაციურ მონაცემთა ბაზის ტრადიციული მეთოდების მეშვეობით ანალიზისათვის საკმაოდ მოცულობითი, დაუმუშავებელი ან არაკონსტრურებულია“ (Kim et al., 2014, с. 78). მონაცემების ინტელექტუალური ანალიზით დაკავებული მეცნიერების დიდი ნაწილი ამტკიცებს, რომ ამ ფორმით, big data 2.0 სამ შიდა მაჩვენებელზეა დაფუძნებული – მოცულობა, სიჩქარე და სხვადასხვაობა ან იმაზე, რასაც ზოგადად big data-ს “3 Vs”-ს უწოდებენ (Lycett, 2013). ზოგიერთმა მეცნიერმა, სამ მაჩვენებლს, რომელზედაც big data-ს განსაზღვრებაა დაფუძნებული, უბრალოდ დაუმატეს სანდოობა და ფასეულობა (Rajaraman, 2016). Joseph Hellerstein-ი, ბერკლის უნივერსიტეტის გამოთვლითი ტექნიკის პროფესორი, ერთ-ერთი პირველთაგანი იყო, ვინც „მონაცემთა სამრეწველო რევოლუციაზე“ მიუთითა (Hellerstein, 2008). IBM-ის შეფასებით, ამჟამად, მსოფლიოში მიღებული მონაცემების თითქმის 90% მხოოლოდ 2 წელიწადშია შეკრებილი, ამასთან ყოველდღიურად მონაცემთა 2,5 კვინტილიონი ბაიტი ემატება (Jacobson, 2013), რაც, რათქმაუნდა, მნიშვნელოვანი ზრდაა.
მონაცემთა საერთაშორისო კორპორაციის უახლეს ტექნიკურ ანგარიშში, მონაცემთა ანალიზის ზოგიერთი ექსპერტის ვარაუდით, big data-ს ბიზნეს ანალიზიდან გლობალური შემოსავლები 2015 წლის $122 მლრდ.-დან 2019 წელს $187 მლრდ. დოლარამდე გაიზარდა, ამასთან 5 წლიან საპროგნოზო პერიოდში ზრდამ 50%-ზე მეტი შეადგინა. მათ, აგრეთვე ხაზი გაუსვეს, რომ მომავალი საინფორმაციო-სამრეწველო კომპლექსის ძირითადი სექტორები, ყველაზე შემოსავლიანი შემოსავლებით, გახდება დისკრეტული წარმოება, საბანკო საქმე და ტექნოლოგიური წარმოება. ამასთან, ისინი ამტკიცებდნენ, რომ სხვა ოთხი სექტორი – ფედერალური/ცენტრალური ხელისუფლება, პროფესიონალური სერვისები, საცალო ვაჭრობა და ტელეკომუნიკაციები – 2019 წლისთვის big data-ში ინვესტიციებიდან დაახლოებით $10 მლრდ. გენერირებას მოახდენენ.
როგორც ანგარიშშია აღნიშნული, საინფორმაციო ტექნოლოგიების სფეროში შემოსავლების ზრდის ყველაზე დიდი ტემპები მოსალოდნელია კომუნალურ სერვისებში, წიაღისეულის მომპოვებელ მრეწველობაში, ჯანდაცვასა და საბანკო საქმეში, თუმცა მსოფლიოში არსებული თითქმის ყველა დარგს, 5 წლიან საპროგნოზო პერიოდში, big data 2.0-ის ინდუსტრიიდან 50%-ზე მეტი ზრდა ექნება.
დიდი ხნის განმავლობაში, მეცნიერები ინტერნეტის, განსაკუთრებით Web 2.0-ის ეპოქაში, პოლიტიკაზე გავლენას სწავლობდნენ. მათ შემოიყვანეს ტერმინი „ვირტუალური პოლიტიკა“, რაც პარალელურ პოლიტიკას მიეკუთვნება, ანუ მოვლენების დიდი ნაწილი ციფრულ საზოგადოებაში ხდება. ერთ-ერთ ასეთ ფენომენს ვირტუალური სოციალური იდენტურობა წარმოადგენდა (Wood and Solo male, 2009). დღეს, პოლიტიკური მარკეტინგის ტერმინებში, შეიძლება ითქვას, რომ პოლიტიკის თითოეული მომხმარებელი უნდა გაერკვეს:
[…] ჩვენი პლანეტის ზედაპირზე არის მისი რეალური პიროვნების ვირტუალური ასლი, რომელიც განსხვავებულ ციფრულ ანაბეჭდებს უმარტივეს ყოველდღიურ საქმიანობაზე ტოვებს, რომლის საშუალებითაც ინტერნეტის ინტელექტუალურ აპლიკაციებთან ურთიერთქმედებს. სიტყვებს, რომელსაც Google-ის საძიებო სისტემით ვეძებთ, ფოტოები, რომელსაც Instagram-ზე მეგობრებს ვუზიარებთ, პროდუქტები, რომელსაც სხვადასხვა ინტერნეტ მაღაზიების საიტებზე ვყიდულობთ და კომენტარები, რომელსაც Facebook-ზე ვტოვებთ, ჩვენ სმარტფონებში არსებული სანავიგაციო რუკების აპლიკაციებით გადავაადგილდებით, მოკლე ტვიტებით Twitter-ზე საკუთარ აზრებსა და გრძნობებს გამოვხატავთ და საინტერესო სამუშაო, რომელსაც LinkedIn-ზე ვეძებთ, ყველაფერი ეს და მრავალი სხვა ნორმალური აქტივობაა, რომელიც ანაბეჭდს ტოვებს და big data 2.0-ზე მონადირეები მის გაკონტროლებას, დახარისხებას, წესრიგში მოყვანას და მანიპულაციას მოწინავე მეთოდებით ცდილობენ. შემდეგ მას ღირებულ, მთელ მსოფლიოში პოლიტიკოსებისათვის სარგებელის მომტან ინფორმაციად გადააქცევენ (Hegazy, 2018, გვ. 8). ამიტომ, big data 2.0 შეიძლება განვიხილოთ, როგორც ყველა პოლიტიკური მარკეტინგული პროცესის ახალი მამოძრავებელი ძალა.
big data 2.0-ის რევოლუციურმა წარმატებამ, სამწუხაროდ პოლიტიკური მარკეტინგის პარადიგმის რამდენიმე დონეზე ცვლილება გამოიწვია. პოლიტიკური მარკეტინგის კონსულტანტების ნაწილი, როგორიცაა, Tactical Tech-ის Hankey (2019) და მისი გუნდი, მაგალითად თვლიან, რომ ძირითადად სოციალური ქსელების აპლიკაციების გზით შეგროვებული პერსონალური მონაცემების გამოყენების სამი ძირითადი მიდგომა არსებობს, რომელიც პოლიტიკური მარკეტინგის სტრატეგიის აგების, რეალიზაციის და შეფასებისას გამოიყენება. ეს მიდგომები პოლიტიკის მომხმარებლებთან უწყვეტ და ეფექტურ კომუნიკაციას უზრუნველყოფს. მასში შედის:
- ფასეული პერსონალური big data-ს ნაკრები, რომელიც პოტენციურ პოლიტიკურ მომხმარებლებსა და ამომრჩევლებზე გადის, სხვათაშორის ამ ინფორმაციას პოლიტიკური მარკეტოლოგები ერთმანეთში ცვლიან და big data-ზე მონადირე კომპანიები ან ზოგიერთი სამთავრობო დაწესებულება ყიდულობს. ეს კატეგორია მოიცავს პერსონალურ big data 2.0-ს ფართო სპექტრს, რომელიც ინტერნეტის ღია სივრცეში ხელმისაწვდომია.
- პერსონალური big data 2.0, რომელიც პოლიტიკური მარკეტოლოგების მიერ მიზანმიმართული მეთოდის მეშვეობით გროვდება და გაანალიზდება, გამოიყენება პოლიტიკის მომხმარებლების პრეფერენციების და დამოკიდებულებების გამოსავლენად, მარკეტინგული სტრატეგიების და ტაქტიკის ინფორმირებისათვის ახალ ახალ ინფორმაციების მიწოდები გზით და არსებული პრიორიტეტების შესაცვლელად. ეს კატეგორია შეიცავს ხელოვნური ინტელექტის და მანქანის სწავლების ფართო ჩამონათვალს, როგორიცაა ციფრული წვდომა, სახეების ამოცნობა, გამოსახულებების ამოცნობა, სკანირება, ტესტირება და პოლიტიკის მომხმარებლის ემოციების და ქცევის ანალიზი.
- Big Data 2.0, როგორც პოლიტიკური გავლენა: Big data 2.0, რომელიც გამოკითხვის ტრადიციული მეთოდებისაგან განსხვავებით, პოლიტიკის მომხმარებლებიდან გროვდება და გაანალიზდება და მათი პოლიტიკური ფასეულობების, შეხედულებების და ქცევის მანიპულირების ან გავლენის მოხდენის მიზნით, მიკრო-ტარგეთისთვის გამოიყენება. შემდეგ პირდაპირი მიკროტარგეთინგის დახმარებით, დაწყებული პროგნოზული ფსიქომეტრიული მოდელირებიდან დამთავრებული სამისამართო სატელევიზიო ტექნოლოგიებს მიეწოდება.
პოლიტიკურ მარკეტინგში პერსონალური big data 2.0-ის დონეების კომბინაცია შესაძლოა პოლიტიკური მარკეტოლოგებისათვის საკმაოდ ძვირადღირებული აღმოჩნდეს. მიუხედავად ამისა, მათი გამოყენების შედეგობრივი გავლენა, განსაკუთრებით ნეირომეცნიერების წამყვანი მეთოდების და ტექნოლოგიების გამოყენებით, ნდობის გამყარებისათვის პოლიტიკური მარკეტინგის სტრატეგიის შემუშავებისას დიდი ალბათობით პოლიტიკური წარმატების საფუძველი გახდება, ვინაიდან პოლიტიკურ მარკეტოლოგს ტრადიციული გამოკითხვების გარეშე, პოლიტიკის მომხმარებლების ფასეულობების, ინტერესების და მოთხოვნების განსაზღვრაში დაეხმარება. პოლიტიკოსები საუკეთესო კუთხით იქნებიან წარმოდგენილები და მომხმარებლების სურვილების და ოცნებების დაკმაყოფილების ერთადერთ აღთმულ ინსტრუმენტად შეიძლება გადაიქცნენ (Niffenegger, 1988). მოგწონთ თუ არა, მაგრამ ეს ფაქტები ნიშნავს, რომ ამჟამად მსოფლიო, მონაცემებზე დაფუძნებული პოლიტიკური მარკეტინგის ყველაზე გათვითცნობიერებული თაობის წინაშე დადდგა. ამიტომ, აუცილებელია პოლიტიკური მარკეტინგის ახალ მიდგომებთან მიმართებაში დამატებითი კვლევითი ძალისხმევების მიღება, რომელიც big data 2.0 ეპოქაში გამოყენებული იქნება.
გაგრძელება იქნება
ავტორი: ტრეისი ჯონსი



